|
|
Robust Dual Gaussian Splatting for Immersive Human-centric Volumetric Videos
We present a novel Gaussian-based representation DualGS for volumetric videos, achieving robust human performance tracking and high-fidelity rendering..
ACM Transactions on Graphics (Proc. of SIGGRAPH Asia), 2024.
[Arxiv]
[Project Page]
[Video]
[bibtex (Coming soon)]
|
|
|
 |
|
V3: Viewing Volumetric Videos on Mobiles via Streamable 2D Dynamic Gaussians
We present a novel approach that enables high-quality mobile rendering through the streaming of dynamic Gaussians. It views the dynamic 3DGS as 2D videos to facilitate the use of hardware video codecs.
ACM Transactions on Graphics (Proc. of SIGGRAPH Asia), 2024.
[Arxiv]
[Project Page]
[Video]
[bibtex (Coming soon)]
|
|
|
 |
|
LetsGo: Large-Scale Garage Modeling and Rendering via LiDAR-Assisted Gaussian Primitives
We introduce a text-driven 3D garment generation framework, DressCode, which aims to democratize design for novices and offer immense potential in fashion design, virtual try-on, and digital human creation.
ACM Transactions on Graphics (Proc. of SIGGRAPH Asia), 2024.
[Arxiv]
[Project Page]
[Video]
[bibtex (Coming soon)]
|
|
|
 |
|
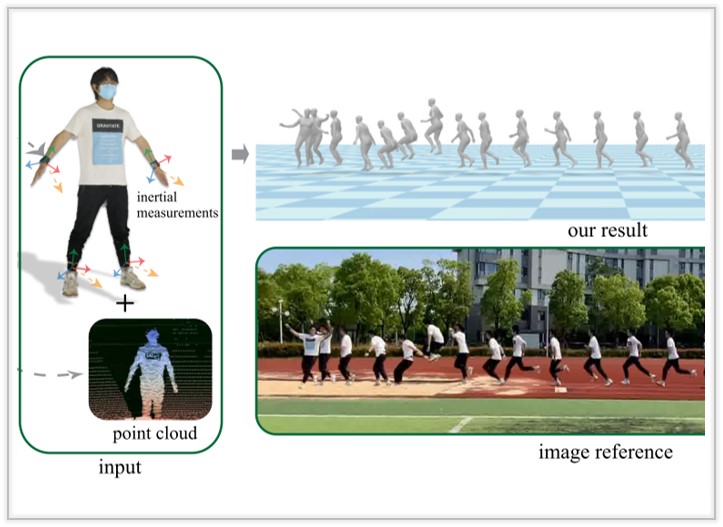
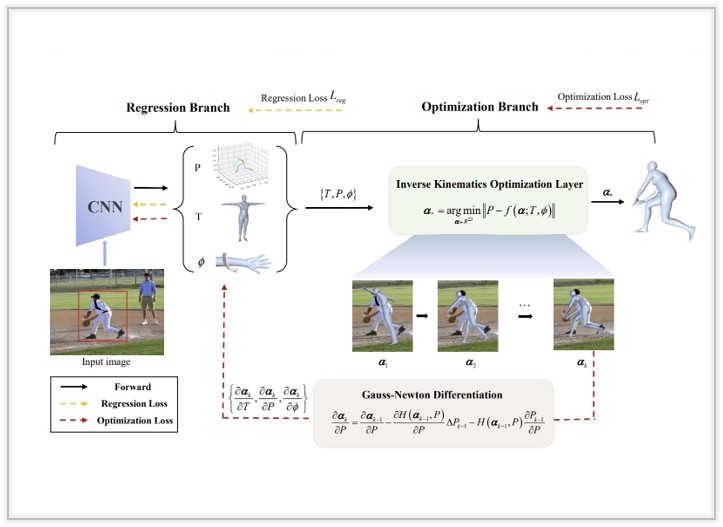
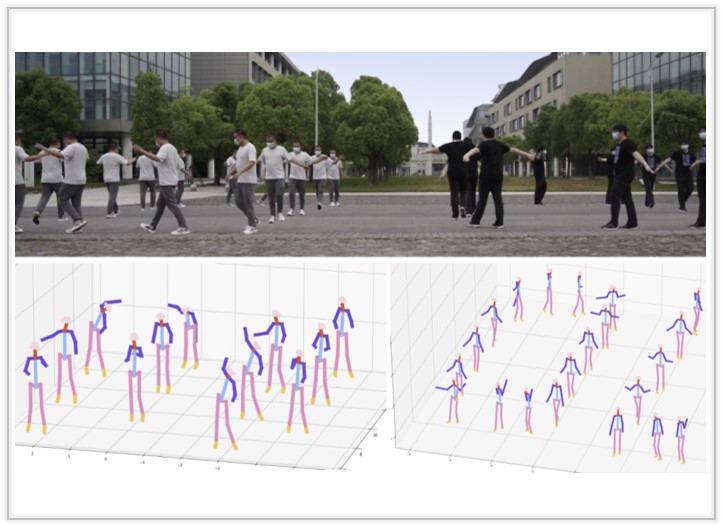
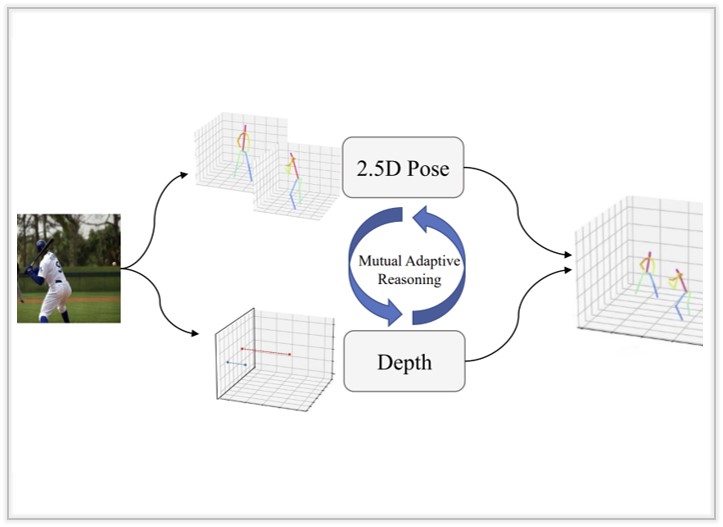
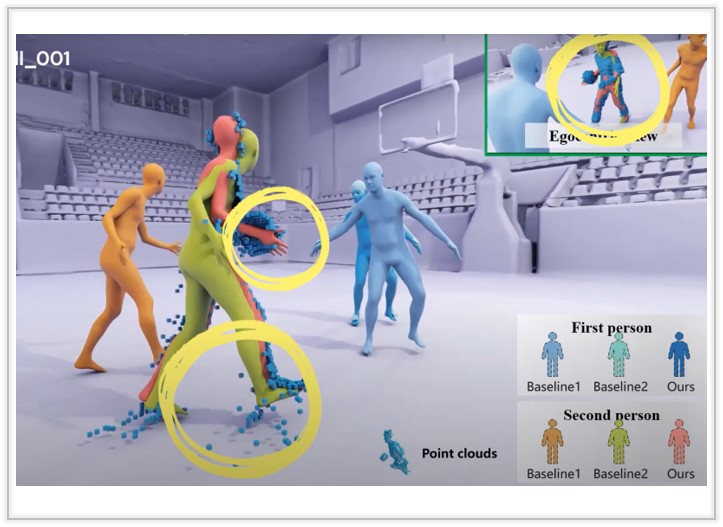
HiSC4D: Human-Centered Interaction and 4D Scene Capture in Large-Scale Space Using Wearable IMUs and LiDAR
We introduce a novel Human-centered interaction and 4D Scene Capture method to creat a dynamic digital world with large-scale indoor-outdoor scenes, diverse human motions, and rich human-human/enviroment interactions.
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2024.
[Paper]
[Project Page]
[Video]
[bibtex]
|
|
|
 |
|
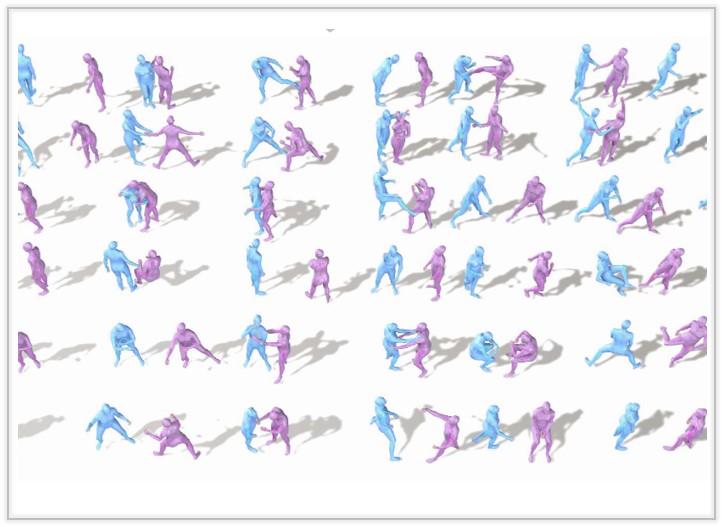
InterGen: Diffusion-based Multi-human Motion Generation under Complex Interactions
We present an effective diffusion-based approach that enables layman users to customize high-quality two-person interaction motions, with only text guidance.
International Journal of Computer Vision (IJCV) , 2024.
[Paper]
[Project Page]
[Video]
[bibtex]
|
|
|
 |
|
CLAY: A Controllable Large-scale Generative Model for Creating High-quality 3D Assets
We introduce a text-driven 3D garment generation framework, DressCode, which aims to democratize design for novices and offer immense potential in fashion design, virtual try-on, and digital human creation.
ACM Transactions on Graphics (Proc. of SIGGRAPH), 2024. Best Paper Honorable Mention
[Paper]
[Project Page]
[Video]
[bibtex]
|
|
|
 |
|
DressCode: Autoregressively Sewing and Generating Garments from Text Guidance
We introduce a text-driven 3D garment generation framework, DressCode, which aims to democratize design for novices and offer immense potential in fashion design, virtual try-on, and digital human creation.
ACM Transactions on Graphics (Proc. of SIGGRAPH), 2024. Best Paper Honorable Mention
[Paper]
[Project Page]
[Video]
[bibtex]
|
|
|
 |
|
Implicit Swept Volume SDF: Enabling Continuous Collision-Free Trajectory Generation for Arbitrary Shapes
We propose a novel hierarchical trajectory generation pipeline, which utilizes the Swept Volume Signed Distance Field (SVSDF) to guide trajectory optimization for Continuous Collision Avoidance.
ACM Transactions on Graphics (Proc. of SIGGRAPH), 2024.
[Paper]
[Project Page]
[Video]
[bibtex]
|
|
|
 |
|
Media2Face: Co-speech Facial Animation Generation With Multi-Modality Guidance
We present a diffusion model in the latent space of the Generalized Neural Parametric Facial Asset, enabling co-speech facial animation generation from rich multi-modality guidances from audio, text, and image. .
Proceedings of the SIGGRAPH Conference, 2024.
[Paper]
[Project Page]
[Video]
[bibtex]
|
|
|
 |
|
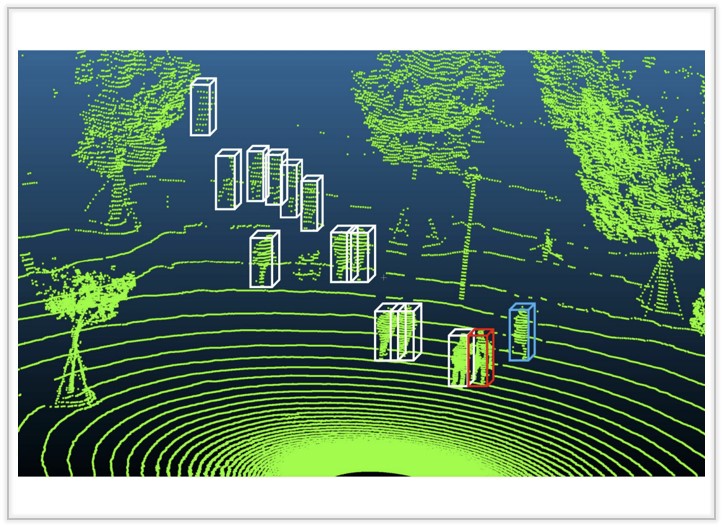
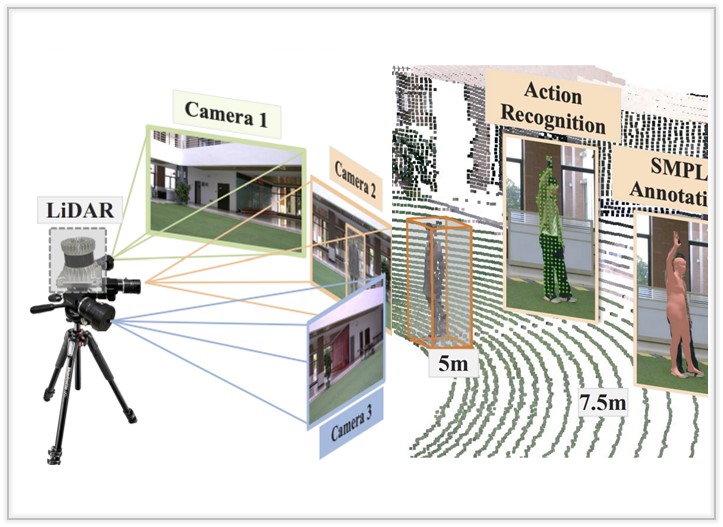
Gait Recognition in Large-scale Free Environment via Single
We propose FreeGait, a new LiDAR-based in-the-wild gait dataset under various crowd density and occlusion across different real-life scenes.
ACM International Conference on Multimedia (ACMMM), 2024. Oral
[Arxiv]
[Project Page (coming soon)]
[bibtex (coming soon)]
|
|
|
 |
|
HmPEAR: A Dataset for Human Pose Estimation and Action Recognition
We propose a novel dataset, named HmPEAR, which integrates imagery and point cloud data for 3D Human pose estimation and human action recognition.
ACM International Conference on Multimedia (ACMMM), 2024.
[Paper (coming soon)]
[Project Page]
[bibtex (coming soon)]
|
|
|
 |
|
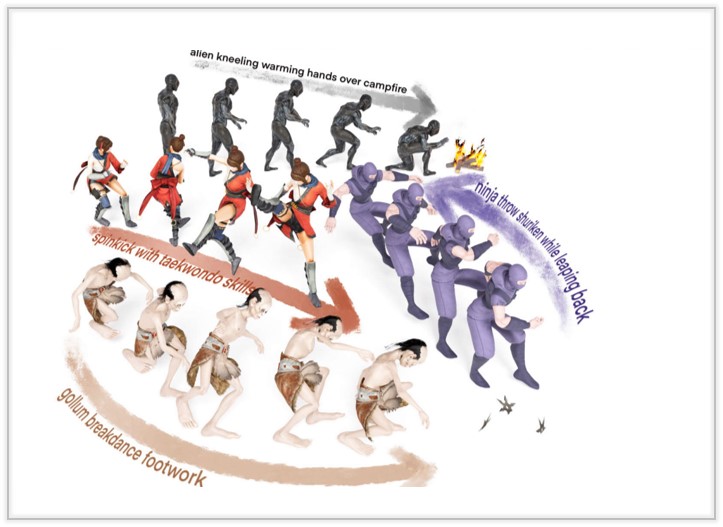
OMG: Towards Open-vocabulary Motion Generation via Mixture of Controllers
We present a progressive scheme to generate personalized 3D faces with text guidance, which can customize 3D facial assets with the desired shape and physically-based textures, as well as empowered animation capabilities.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024.
[Paper]
[Project Page]
[Video]
[bibtex]
|
|
|
 |
|
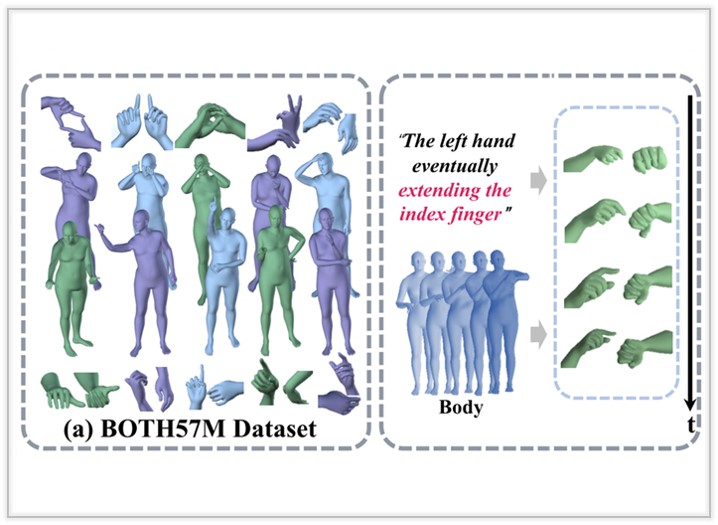
BOTH2Hands: Inferring 3D Hands from Both Text Prompts and Body Dynamics
We present a progressive scheme to generate personalized 3D faces with text guidance, which can customize 3D facial assets with the desired shape and physically-based textures, as well as empowered animation capabilities.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024.
[Paper]
[Project Page]
[Video]
[bibtex]
|
|
|
 |
|
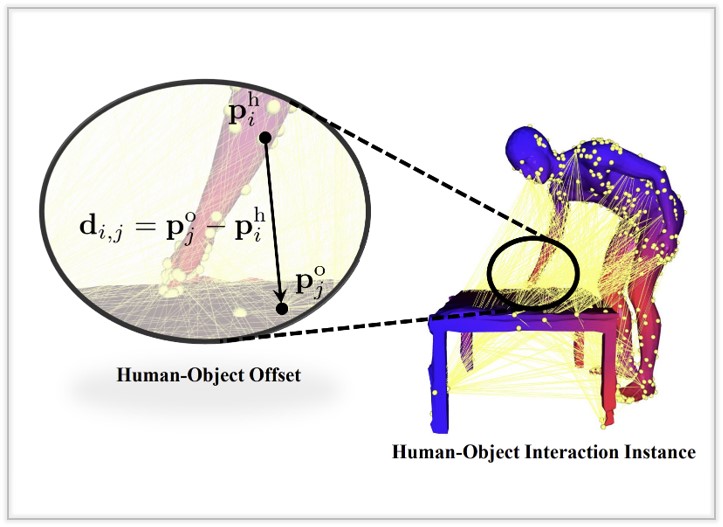
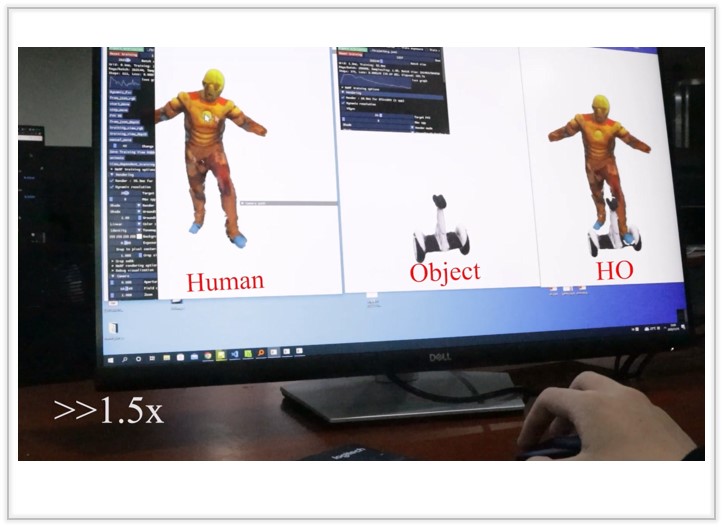
I'M HOI: Inertia-aware Monocular Capture of 3D Human-Object Interactions
We present a progressive scheme to generate personalized 3D faces with text guidance, which can customize 3D facial assets with the desired shape and physically-based textures, as well as empowered animation capabilities.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024.
[Paper]
[Project Page]
[Video]
[bibtex]
|
|
|
 |
|
HiFi4G: High-fidelity human performance rendering via compact gaussian splatting
We present a progressive scheme to generate personalized 3D faces with text guidance, which can customize 3D facial assets with the desired shape and physically-based textures, as well as empowered animation capabilities.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024.
[Paper]
[Project Page]
[Video]
[bibtex]
|
|
|
 |
|
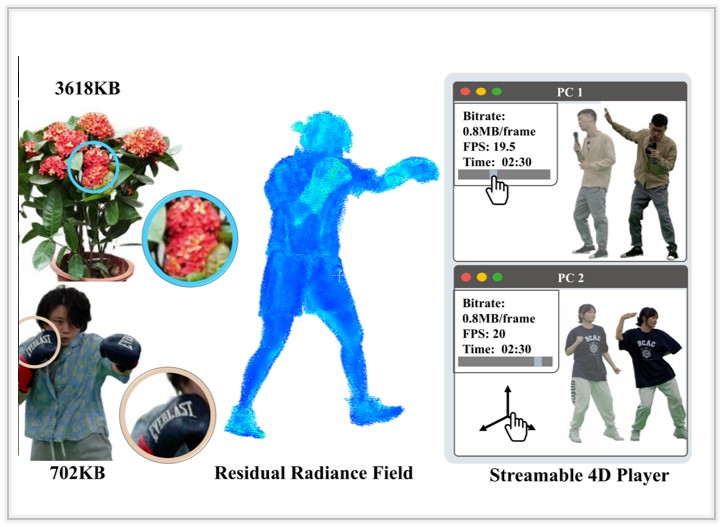
VideoRF: Rendering Dynamic Radiance Fields as 2D Feature Video Streams
We present a progressive scheme to generate personalized 3D faces with text guidance, which can customize 3D facial assets with the desired shape and physically-based textures, as well as empowered animation capabilities.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024.
[Paper]
[Project Page]
[Video]
[bibtex]
|
|
|
 |
|
HOI-M^3: Capture Multiple Humans and Objects Interaction within Contextual Environment
We introduce HOI-M3, a novel large-scale dataset for modeling the interactions of Multiple huMans and Multiple objects, covering 199 sequences and 181M frames of diverse humans and objects under rich activities.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024.
[Paper]
[Project Page]
[Video]
[bibtex]
|
|
|
 |
|
RELI11D: A Comprehensive Multimodal Human Motion Dataset and Method
We present RELI11D, a high-quality multimodal human motion dataset involves RGB camera, Event camera, LiDAR and IMU system. It records the motions of 10 actors performing 5 sports in 7 scenes and 3.32 hours.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024.
[Paper]
[Project Page]
[Video]
[bibtex]
|
|
|
 |
|
LiveHPS: LiDAR-based Scene-level Human Pose and Shape Estimation in Free Environment
We present LiveHPS, a novel single-LiDAR-based approach for 3D HPS in large-scale scenarios, which is not limited to fixed studios, light conditions, and wearable devices.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024.
[Paper]
[Project Page]
[Video]
[bibtex]
|
|
|
 |
|
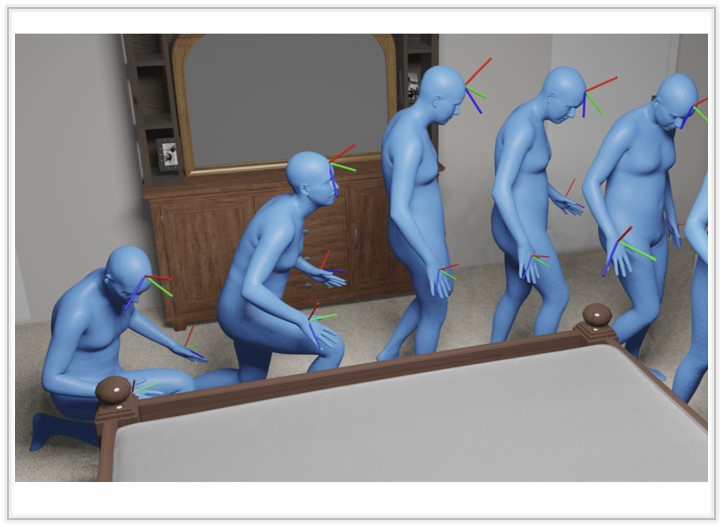
A Unified Diffusion Framework for Scene-aware Human Motion Estimation from Sparse Signals
We introduce a unified diffusion method, S2Fusion, tailored for the scene-aware human motion estimation with sparse signals.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024.
[Paper]
[Project Page]
[Video]
[bibtex]
|
|
|